
Self-supervised Learning for Computer Vision and Chemistry
컴퓨터 비전과 화학 분야를 위한 self-supervised learning
KAIST Algorithmic intelligence 연구실에 있는 이한국 박사의 발표를 토대로 작성된 글입니다.
Self-supervised Learning 이란?
deep neural network는 일반적으로 label이 있는 데이터로부터 학습이 됩니다.
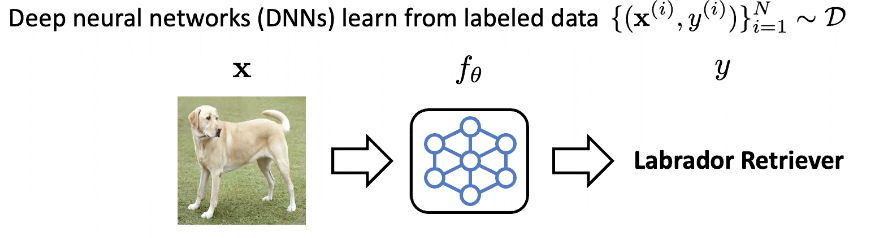
D는 data distribution을 의미하고 x와 y는 각각 data와 label을 의미합니다. 위의 그림에서는 neural network가 이미지를 입력으로 받아, 오브젝트의 카테고리를 분류하도록 학습하게 됩니다. 하지만 좋은 label 정보를 얻는 것은 현실적으로 어려운 경우가 많고 비용이 많이 드는 경우가 있습니다. 따라서 deep-learning에서 아주 중요한 질문 중 하나는 label이 없이도 neural network를 잘 학습할 수 있는가 입니다. 이러한 문제를 unsupervised learning이라 부릅니다.
label 정보가 있는 label 데이터와 다르게 unlabeled 데이터는 세상에 아주 많고 구하기 쉽습니다. 만약 우리가 이런 많은 데이터로부터 deep neural network를 잘 학습시킬 수 있다면, 이렇게 학습한 네트워크를 다양한 task에 활용할 수 있게 됩니다. 이렇게 label 정보를 사용하지 않고 모델을 학습시킬 수 있는 방법론 중 하나로 최근에 각광 받고 있는 분야가 자기 지도 학습(Self-supervised learning)입니다. 원래의 input 데이터를 이용하여 input label pair x, y를 만들어 주는 것입니다.
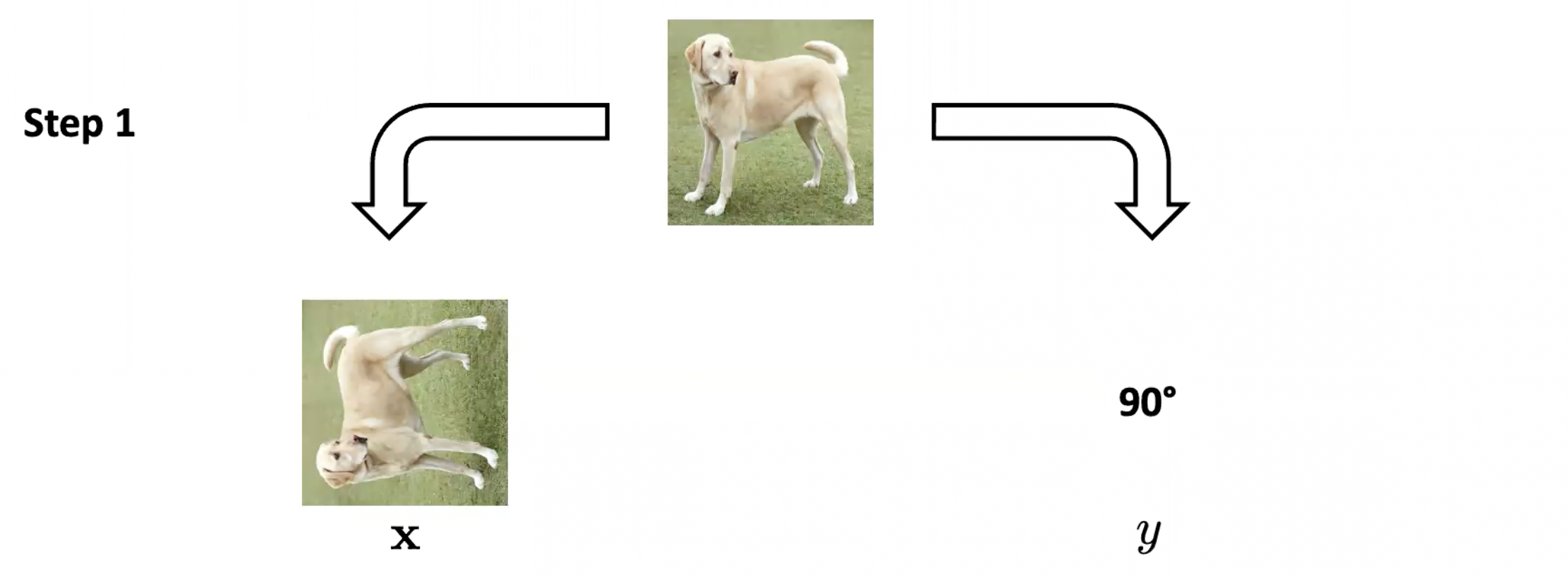
다음 예제의 경우 이미지를 회전시켜서 회전된 이미지를 input으로, 회전된 각도를 label로 생각합니다. 이후, 회전 각도를 예측하는 문제를 풀도록 신경망 neural network를 학습시킵니다. 원래의 이미지를 사용하였고, 사람이 직접 매기는 label을 사용하지 않았으며, supervised learning 처럼 학습하였기 때문에 이러한 방법론을 self-supervised learning이라고 부릅니다. 이렇게 이미지에 회전을 주는 것 이외에도 이미지의 일부를 마스킹하고, 마스킹 된 부분을 예측하는 mask image prediction 문제를 해결하기도 합니다. 이미지에 대한 label이 없이도 해당 부분에 대해 prediction을 하기 위해서는 neural network가 이미지에 대한 domain knowledge를 알고 있어야 하는데, 이는 self-supervised learning을 통해 이루어집니다.
How to construct effective self-supervision for various domains/applications?
1. computer vision

데이터 증강(Data augmentation)은 컴퓨터 비전 도메인에서 deep neural network를 학습할 때 널리 사용되는 기법 중 하나입니다. Data augmentation이란 단순히 원래의 데이터 x를 비슷한 데이터x'으로 바꾸어 주는 것을 말합니다. 그림처럼 이미지를 찌그러트리기도 하고 뒤집거나 회전시키기도 하며 색깔을 바꾸어 주기도 합니다. 이러한 데이터 증강은 데이터의 수를 늘려주는 효과가 있기 때문에 over fitting을 완화하는 효과가 있습니다.
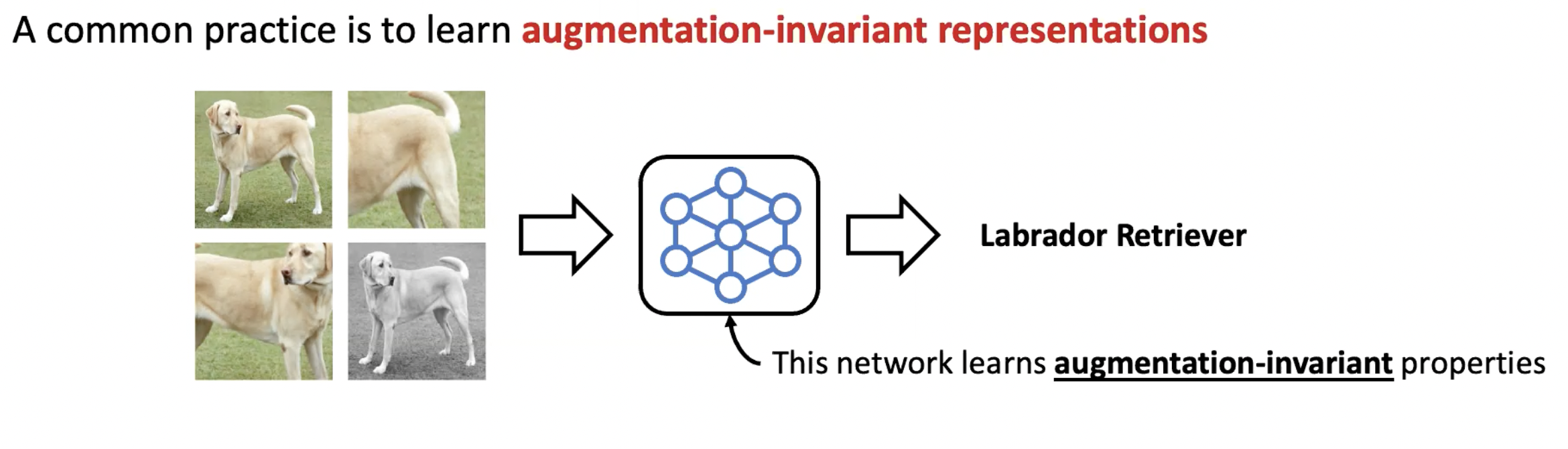
일반적으로 data augmentation을 사용하는 방법은 augmentation-invariant feature 혹은 representation을 학습하는 것입니다. 예를 들어 다양하게 augmentation 된 리트리버의 사진에 대해 전부 같은 label을 매겨 network는 증강에 상관 없이 항상 같은 label을 예측하도록 하는 것입니다. 그렇다면 왜 augmentation-invariance만 고려를 하는 것일까요?
다음의 예시를 확인해 봅시다.
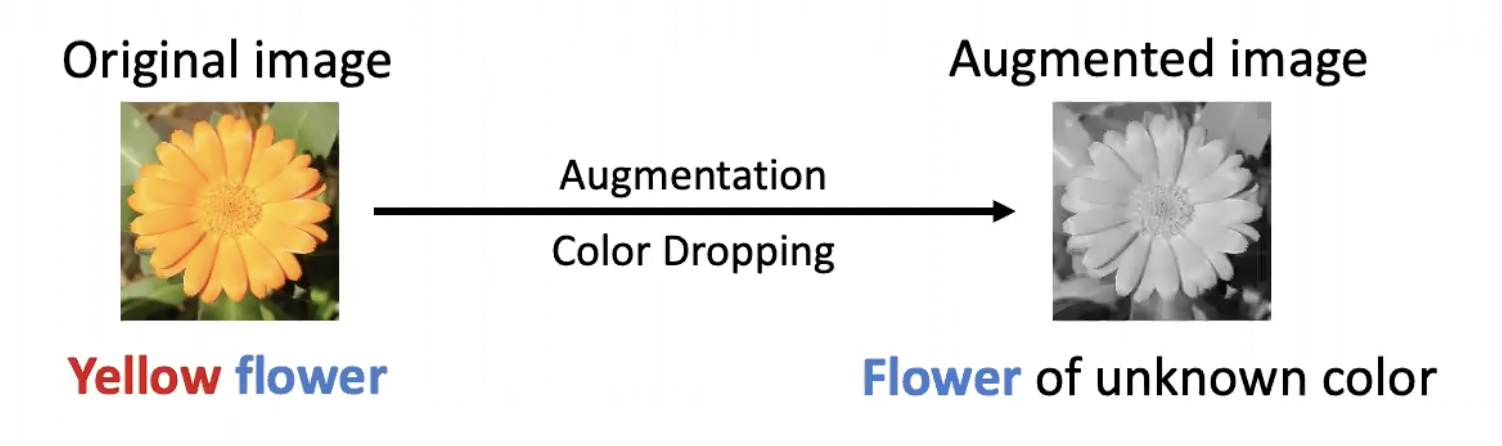
원래의 이미지가 노란색 꽃이고 color dropping augmentation 기법을 사용한다면 바뀐 이미지는 색깔을 모르는 꽃이 됩니다. 이때 augmentation과 상관 없는 정보는 꽃이고, augmentation과 관련 있는 정보는 노란색이 됩니다. 그렇다면 색처럼 augmentation과 관련 있는 정보는 중요하지 않을까요? 그렇지 않습니다. 우리가 어떤 downstream tasks를 목표로 하느냐에 따라 augmentation과 관련 있는 정보는 매우 중요할 수도 있는데요, 예를 들어 아까의 예시에서 색깔에 invariant한 representation을 학습했기 때문에 각각의 꽃 색깔이 어떻게 되는지 알기 어려워집니다. 이는 꽃 분류 문제와 같이 color 정보에 민감한 downstream task를 풀려고 할 때 성능에 영향을 미칠 수 있습니다. 다시 말해, augmentation과 관련 있는 정보는 augmentation에 민감한 특정 task에 매우 중요할 수도 있습니다.
어떻게하면 augmentation-invariant한 정보를 잘 배우면서 동시에 augmentation-aware한 정보도 잘 학습할 수 있을까요?
[Self-supervised Label Augmentation via input transformations, ICML’20]
augmentation-aware한 정보를 학습하는 가장 간단한 방법은 augmentation이 어떻게 되었는지 label로 사용하여 self-supervised learning을 하는 것입니다.
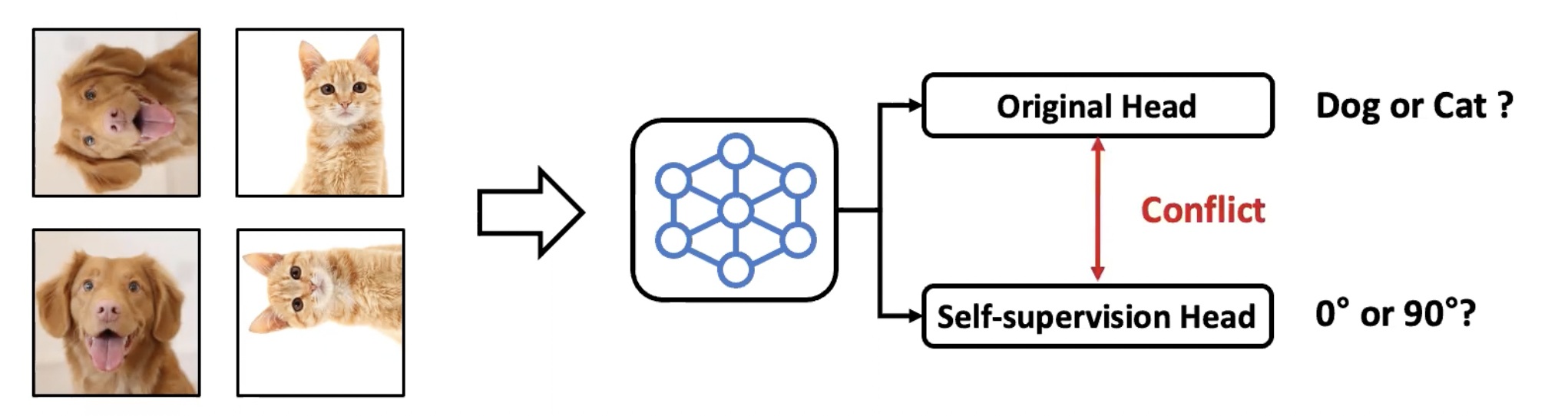
기존의 논문들은 원래의 task와 self-supervised learning을 두개의 브랜치로 나누어 학습하는 일반적인 multitask learning 방법론을 사용하였는데요, 이러한 방식은 데이터에 모든 label이 있는 경우에는 잘 동작하지 않습니다. 그 이유는 기존 classification task에서는 augmentation에 대한 invariance를 학습하려 하고, self-supervised learning task에서는 augmentation에 sensitive한 정보를 학습하려 하기 때문에 두 개의 task가 서로 충돌이 나고 학습에 방해가 되기 때문입니다.
두 task의 충돌을 근본적으로 없애기 위한 방법으로 Joint-label을 정의하고 이를 예측하는 classifier를 정의하는 Self-supervised Label Augmentation (SLA)방법을 사용했습니다. Original label이 N 개가 있고 Self-supevised label이 M 개가 있다면 총 N * M 개의 label이 생기게 됩니다. 이러한 방법은 간단하지만 효과적이기 때문에 다양한 out of distribution detection이나 gen training 혹은 knowledge distribution과 같은 문제에서도 활용됩니다.
[Improviing Transferability of Representations via Augmentation-Aware Self-Supervision, NeurlPS’21]
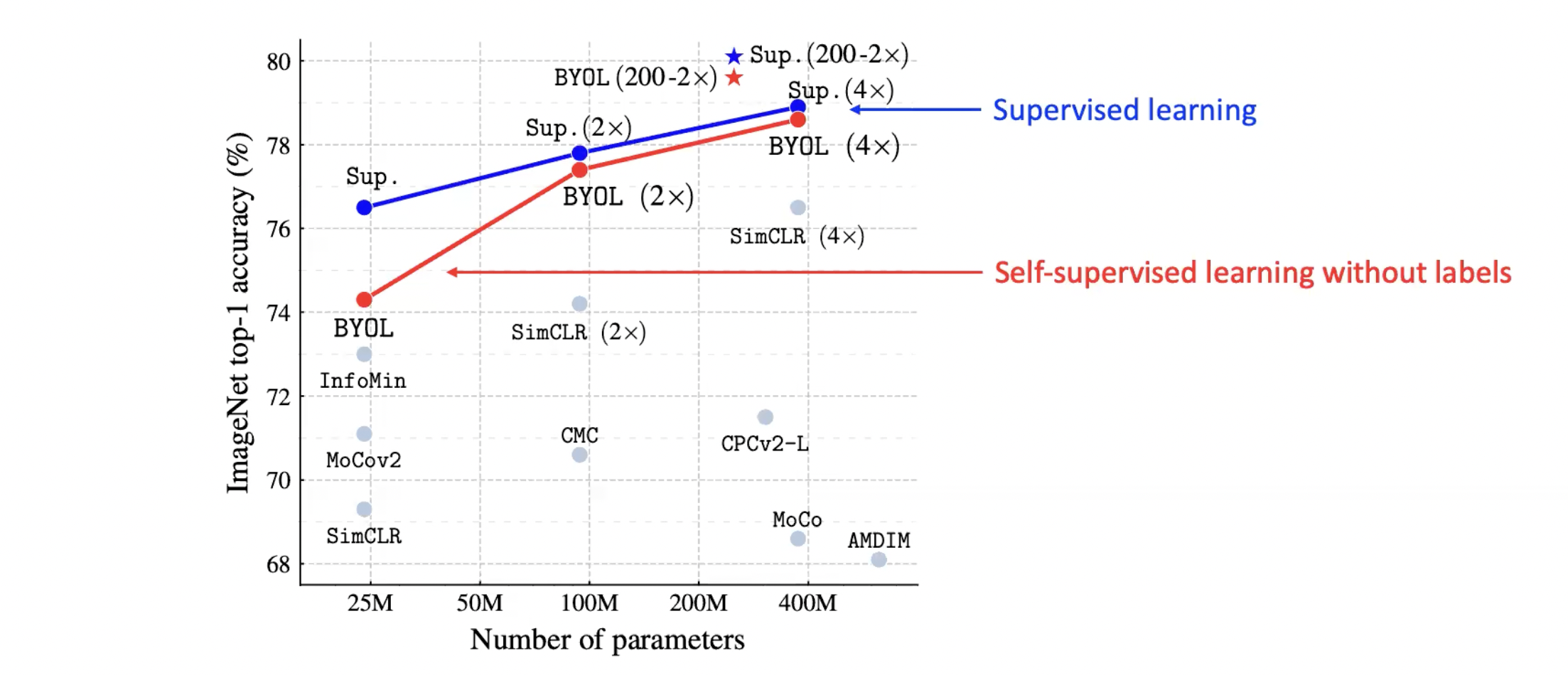
그림에서 보실 수 있듯이 label을 사용하지 않고 self-supervised learning을 사용하였을 때 network가 배우는 knowledge와 사람이 직접 매긴 label을 사용하였을 때 배우는 knowledge가 비슷하다는 결과가 최근 논문에서 많이 발표가 되고 있습니다.
augmentation sensitive한 정보를 잘 학습하게 하기 위해서, augmentation된 이미지를 입력으로 받아서 augmentation parameter를 역으로 예측하는 방법 AugSelf를 사용했습니다.
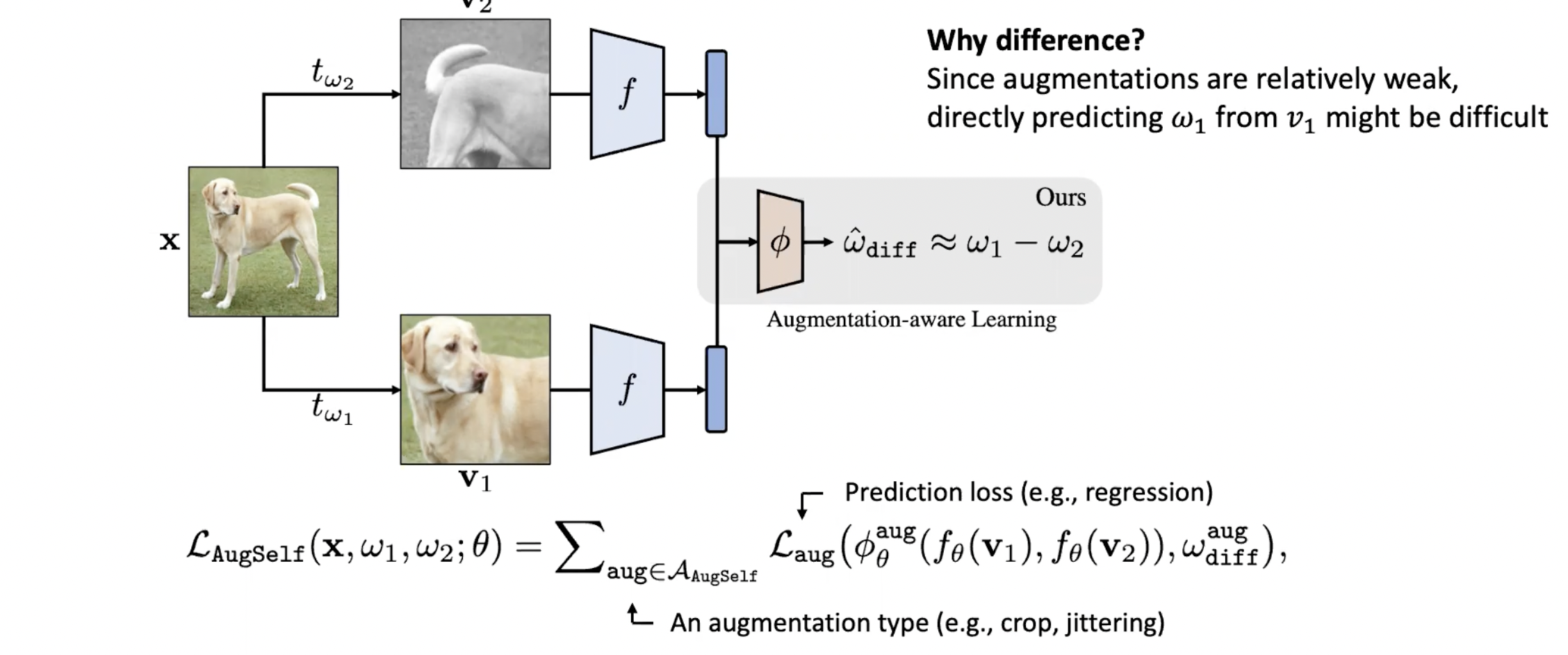
두 개의 augmentation된 이미지 v1 과 v2 로 부터 resNet과 같은 convolution network를 사용하여 fv1 과 fv2를 얻고, 이렇게 얻어낸 두 representation으로 부터 두 augmentation parameter의 차이를 예측하는 것입니다. 여기서 차이를 예측하는 이유는 하나의 뷰, v1으로부터 ω1을 바로 예측하는 것은 augmentation이 약하게 적용되었을 경우 어떻게 augmentation이 되었는지 예측하는 것은 어렵기 때문입니다.
[Patch-level Representation Learning for Self-supervised Vision Transformers, CVPR’22]
Dense prediction task란 기존의 classification 문제처럼 이미지 하나에 대하여 하나의 prediction만 하는 것이 아니라 pixel마다 혹은 object마다 prediction을 해야 하는 문제로 object detection, sementic segmentation 등이 있습니다. 이러한 문제에 대해 labeling을 하는 것은 모든 pixel 혹은 모든 object에 대해 annotation이 있어야 하기 때문에 이러한 label을 모으는 데 비용이 많이 필요합니다.
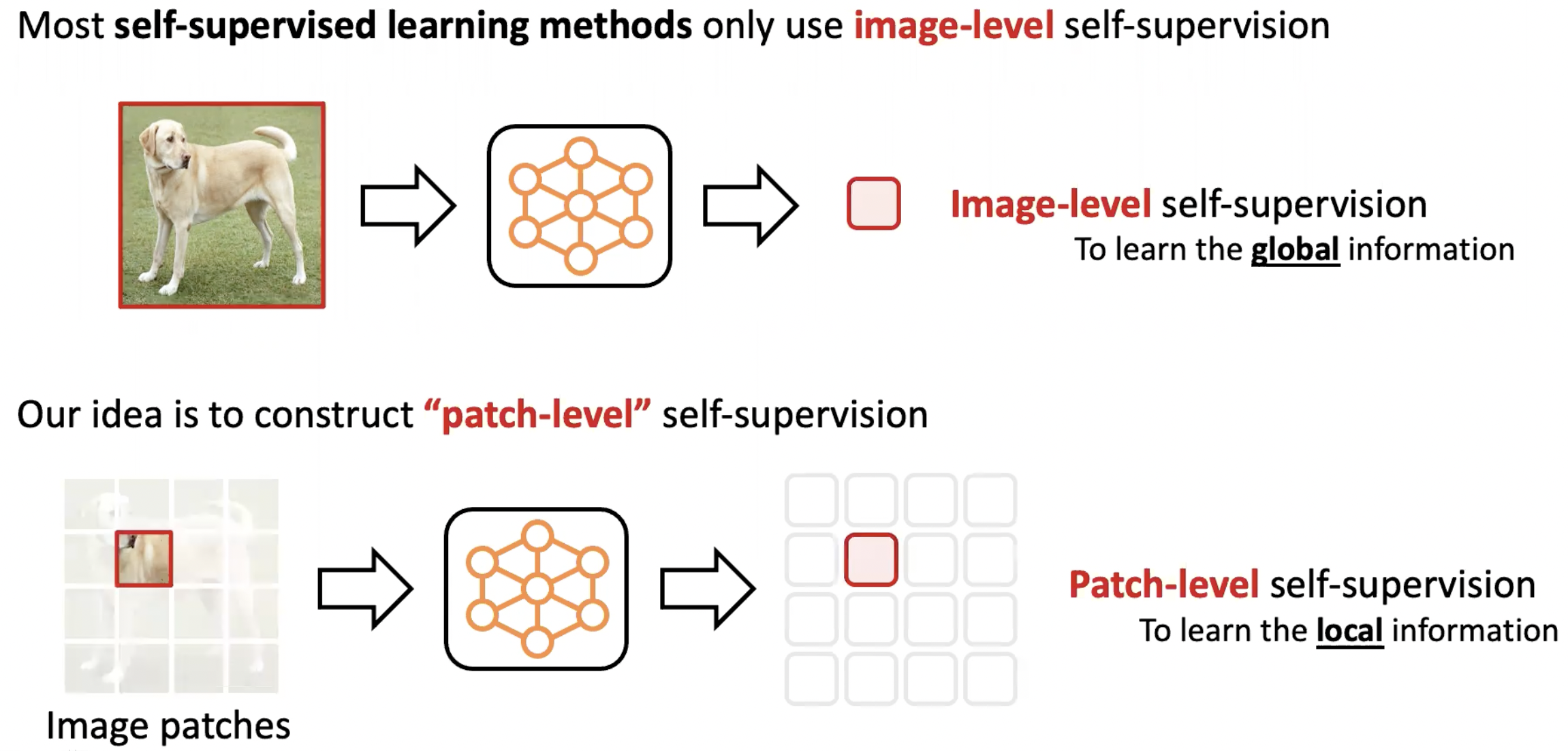
대부분의 self-supervised learning 방법들은 image-level self-supervision을 개발하고 학습하는데 집중하였습니다. 즉 이러한 방법론들은 global information을 배우는데 적합합니다. 하지만 dense prediction task를 하기 위해서는 local information을 학습해야 하는데, patch-level self-supervision을 사용하여 이러한 문제를 해결하였습니다.
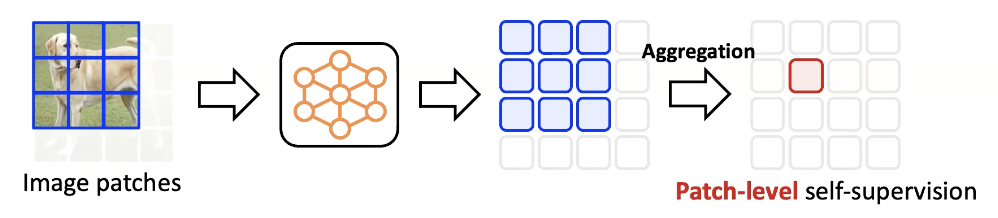
patch-level supervision을 만들기 위해서는 인접한 patch들은 모두 비슷한 semantic context를 가진다는 도메인 knowledge를 사용해야 합니다. 각 patch마다 주위 patch들을 선택하고 해당 patch들의 representation을 neural network를 이용하여 도출해 냅니다. 이후 파란색으로 색칠 된 patch들의 representation을 하나로 합치는 작업을 합니다. 이렇게 만들어진 빨간색 representation은 여러 representation을 하나로 합쳤기 때문에 상대적으로 조금 더 좋은 quality의 representation이 될 것이고, 파란색 patch들 중 가운데 있는 patch의 supervision으로 사용되게 됩니다.
2. Chemistry
Chemistry 도메인에는 아주 흥미로운 문제들이 많이 있고 산업 혹은 사회의 다양한 문제에 아주 밀접한 연관을 가지고 있습니다. 예를들어 새로운 분자를 발견하는 문제는 새로운 약을 개발하거나 특정 재료를 개발하는데 핵심적인 역할을 합니다. 그렇다면 machine learning은 왜 이러한 화학 문제에 중요할까요? 가장 대표적인 장점은 개발 과정을 축소시키고 개발 비용을 감소시킬 수 있다는 점입니다.
[Guiding Deep Molecular Optimization with Genetic Exploration, NeurlPS’20]
De Novo Molecule Design에서 De Novo는 “새로운”이라는 뜻의 라틴어로, 새로운 분자 구조를 디자인하는 task를 말합니다. 아무 분자나 새로 디자인 하는 것이 아니라 원하는 분자의 물성을 가질만한 분자 구조를 찾아내는 것이 목적인데요 예를들어 특정 약을 개발한다고 했을 때 약으로 잘 동작하기 위한 특정 성질이나 용해성들을 가지는 분자 구조를 사용하는 것입니다.
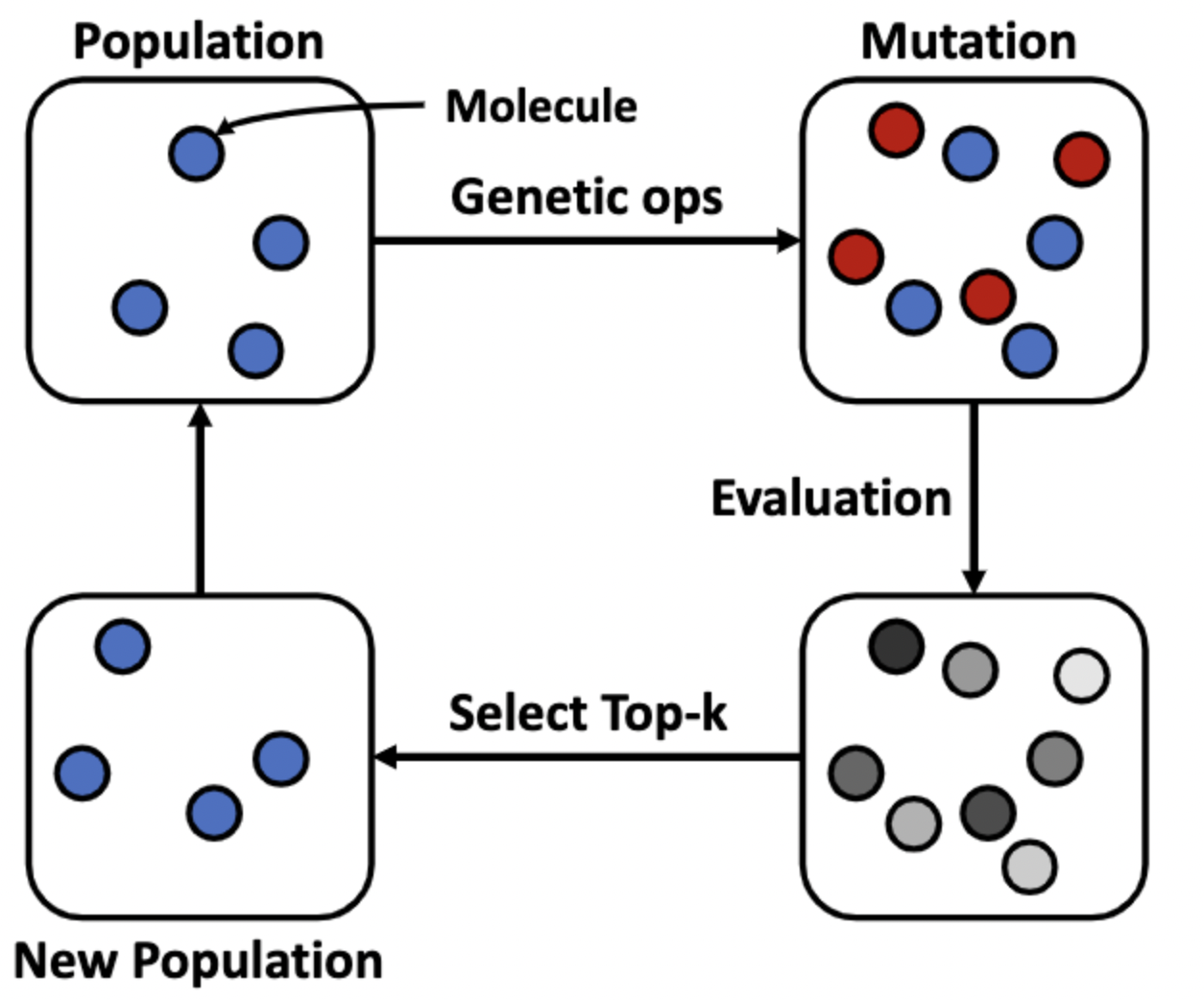
분자 구조 디자인 알고리즘 중 가장 대표적인 것은 Genetic Alogirithms (GAs) 입니다. 분자 구조의 초기 set으로부터 시작해서 genetic operation을 적용하여 분자 구조를 약간씩 변형하여 다양한 분자 구조를 만드는 방법입니다. 새로운 atom을 추가하거나 없애는 방식을 사용하는데요, 새롭게 만들어진 분자 구조들을 target objective를 사용하여 평가하고 좋다고 판단되는 분자들만 남기는 과정을 반복하여 가지고 있는 molecule set은 점점 좋아지는 방향으로 변하게 됩니다.
[Self-Improved Retrosynthetic Planning, ICML’21]
역합성(Retrosynthesis)이란 target molecule이 주어졌을 때 이를 합성하기 위한 합성 경로를 찾는 문제인데요, 역합성 알고리즘은 비용이 절감되는 합성 경로를 찾는데 유용합니다. 어떠한 화학 반응이 합성에 효과적인지 알 수 없고, 최종 building block들은 시중에서 구매가 가능한지 등을 고려해야 하기 때문에 매우 어려운 문제입니다.
역합성 문제에서는 화학 반응식을 순차적으로 예측해야 하기 때문에 Monte Carlo Tree Search(MCTS)와 같은 tree search 알고리즘을 주로 사용합니다.
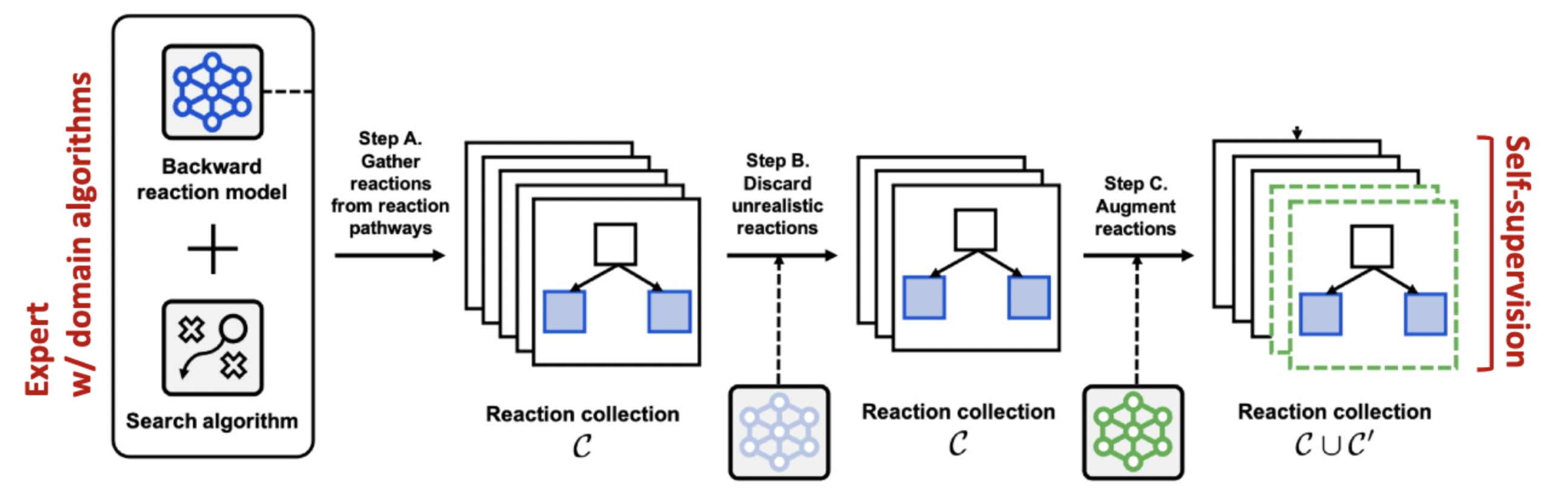
tree search 알고리즘과 path prediction 모델을 사용하여 다양한 합성 경로를 찾습니다. 이후 비현실적인 합성 경로는 제거하고, 나머지 합성 경로들은 augmentation해 줍니다. 마지막으로, 만들어진 효과적인 합성 경로들을 잘 예측할 수 있도록 path prediction 모델을 학습시켜 줍니다.
댓글남기기